DataScience Training
 Riprodurre l’audio
Riprodurre l’audio 



|
Scienza dei dati & Impatto Sociale: Ottenere risultati positivi Introduzione Perché dovresti seguire questo corso Click to read
 La scienza dei dati e l'intelligenza artificiale hanno una grande varietà di applicazioni con un impatto sociale positivo. Ad esempio, la scienza dei dati è utile per indagare su come i social media influenzino i diritti umani. D'altra parte, la scienza dei dati e le applicazioni di IA comportano anche rischi per la salute, la sicurezza, l'ambiente e i diritti umani. Pregiudizi e discriminazioni, preoccupazioni sulla privacy e impatti ambientali dannosi sono solo alcuni dei possibili effetti. Al fine di garantire che le applicazioni della scienza dei dati vadano a beneficio delle persone e del pianeta, è necessario comprendere sia le sue capacità che i suoi rischi. In questo corso, sarete verranno illustrati entrambe gli aspetti, e verranno anche introddi alcuni metodi utili a fronteggiarne i rischi.
Utilizzare la scienza dei dati per il bene sociale Panoramica della possibile scienza dei dati per buoni casi d’uso Click to read
Il modo migliore per comprendere l’impatto positivo che la scienza dei dati può avere sulle persone e sul pianeta è guardare alcuni esempi del recente passato. Il rapido ritmo del cambiamento tecnologico sta anche innescando cambiamenti nel mercato del lavoro - i vecchi posti di lavoro e le professioni stanno scomparendo e vengono sostituiti da quelli nuovi. Ciò ha l’effetto di causare disoccupazione in alcuni settori, mentre in altri, i datori di lavoro hanno difficoltà a trovare dipendenti qualificati. Ma in realtà, molte competenze acquisite nei settori “in via di estinzione” potrebbero essere facilmente adattate e riutilizzate in nuovi settori. Nel progetto pilota SkillsFuture Singapore, la scienza dei dati viene utilizzata per individuare tali competenze “riutilizzabili” e aiutare i disoccupati con corsi di formazione mirati a riallineare le loro competenze con le esigenze dei settori industriali in espansione. L’intelligenza artificiale può anche essere utilizzata per migliorare la capacità predittiva dei gemelli digitali, ad esempio per contribuire a rendere la catena di approvvigionamento più resiliente. I gemelli digitali utilizzano i dati a disposizione di un’azienda - sia i dati generati internamente attraverso processi operativi, transazionali o di altro tipo, sia quelli disponibili al pubblico come il monitoraggio meteorologico - per simulare la catena di approvvigionamento. I sistemi di intelligenza artificiale formati con l’apprendimento di rinforzo possono essere aggiunti a questi gemelli digitali, consentendo alle aziende di esplorare gli effetti di diversi scenari “cosa succede se”, come l’impatto di un tornado, e sviluppare misure per reagire a tali scenari [2]. I sistemi di IA possono essere utilizzati in una varietà di modi per lavorare per raggiungere gli obiettivi climatici. Ad esempio, Fero Labs utilizza l’intelligenza artificiale per aiutare i produttori di acciaio a ridurre l’uso di ingredienti estratti fino al 34 %, impedendo circa 450.000 tonnellate di emissioni di CO2 all’anno, mentre il Mapping the Andean Amazon Project utilizza l’intelligenza artificiale per monitorare la deforestazione tramite immagini satellitari per aiutare a scoprire la deforestazione illegale e sostenere le risposte politiche [3]. Una delle sfide associate ai veicoli elettrici è che richiedono l’accesso a infrastrutture elettriche appositamente progettate per loro, vale a dire le stazioni di ricarica elettrica. Se molte auto hanno bisogno della stessa infrastruttura allo stesso tempo, questo può rappresentare una sfida significativa per la rete elettrica. Prendendo in considerazione l’idea - uno degli ostacoli all’adozione su larga scala di fonti di energia rinnovabili è la grande fluttuazione della disponibilità di energia e la capacità limitata di immagazzinare l’elettricità ai tempi di massima disponibilità, al fine di distribuirla nei momenti di maggior utilizzo. Le tecnologie Veicolo di rete, che consentono alle auto elettriche di essere utilizzate come “stoccaggio” per eccesso di energia, e di permettere alla rete di attingere energia dalle auto quando le auto non sono in uso, possono contribuire a mitigare il problema. Utilizzando l’AI, Caltech ha sviluppato un sistema di ricarica adattiva che programma quando caricare quale veicolo, e quando e quanta energia può essere richiamata nella rete, in base agli orari di partenza inviati dal conducente. Ciò riduce lo stress complessivo posto sulla rete elettrica e apre l’interessante possibilità per le auto elettriche di alleviare effettivamente parte dell’onere sulle reti elettriche [4]. Le catene di approvvigionamento sono incredibilmente complesse, il che è una sfida per la legislazione come l’Uyghur Forced Labor Prevention Act degli Stati Uniti che mira a far rispettare standard sociali o ambientali più elevati nei prodotti. Altana Atlas combina le informazioni geolocalizzate sulle sedi e le strutture aziendali con i dati di proprietà aziendale per mappare le relazioni commerciali tra i settori. Ciò aiuta le aziende a rispettare tale legislazione in modo più efficace e ad agire da soli contro problemi come il lavoro forzato [5]. Le turbine eoliche sono un’importante fonte di energia rinnovabile, ma la loro produzione dipende da un fattore difficile da controllare: il vento. Ciò pone una sfida per la rete energetica, ma anche per il reparto vendite dei fornitori di energia eolica, in quanto l’energia che è più prevedibile può anche raggiungere prezzi più elevati. Per supportare il caso aziendale dei parchi eolici, DeepMind ha sviluppato una rete neurale addestrata sulle previsioni meteorologiche e sui dati operativi storici in grado di prevedere la produzione del parco eolico con 36 ore di anticipo, ottenendo così un valore superiore del 20 % per l’energia prodotta [6].
Amnesty Italia_Il caso Click to read
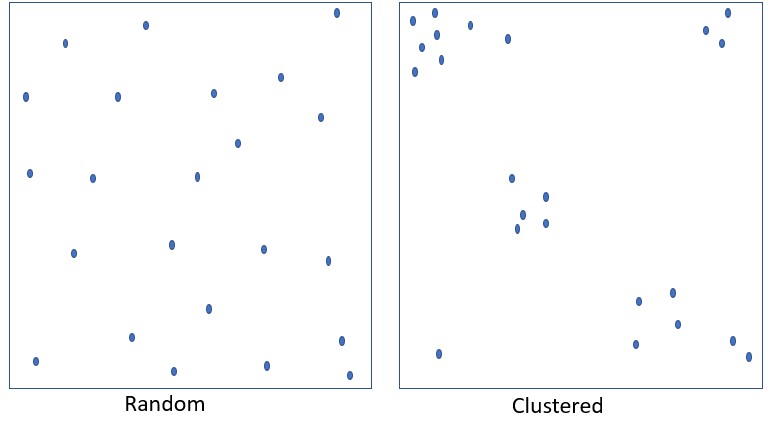
I social media sono una parte importante della sfera pubblica. Per indagare come si sta sviluppando il discorso politico sulle questioni relative ai diritti umani e come questo influisce sui gruppi svantaggiati, Amnesty International Italy conduce il monitoraggio chiamato Barometro dell’Odio (Barometro dell’Odio) ogni anno utilizzando tecniche della scienza dei dati. Esempio: Elezioni del Parlamento europeo 2019 La scienza dei dati non è sempre buona
L’ Hate Speech non è distribuito in modo casuale: Ogni rettangolo ha lo stesso numero e la stessa dimensione di punti blu
Secondo i dati di Amnesty Italia, la prevalenza dell'incitamento all'odio online è di circa l'1 %. Ma tende ad essere focalizzata su particolari gruppi e argomenti. E ha anche picchi di concentrazione nel tempo.
Argomenti di Hot Rod: Immigrazione/Asilo/Rifugiati; Roma; Minoranze religiose; Donne e i loro diritti...
La scienza dei dati non è sempre buona Principali esempi noti Click to read
Sfortunatamente, proprio come qualsiasi altra tecnologia, l’intelligenza artificiale e la scienza dei dati possono anche essere utilizzate per scopi negativi o avere conseguenze indesiderate. Tuttavia, a differenza di altri strumenti, l’intelligenza artificiale automatizza le decisioni per noi, e quindi ha un potenziale ancora maggiore di causare danni. Pertanto, dobbiamo anche essere consapevoli che l’IA e la scienza dei dati possono avere un impatto negativo sugli esseri umani, sulla società e sull’ambiente. 1. Gli ospedali negli Stati Uniti ora fanno affidamento su algoritmi per valutare il grado di malattia dei pazienti, al fine di determinare se hanno bisogno di cure ospedaliere o ambulatoriali. Uno studio ha scoperto che le valutazioni di un sistema molto ampiamente utilizzato erano distorte in modo razziale: I pazienti neri erano infatti più malati dei pazienti bianchi che avevano ricevuto lo stesso punteggio di rischio. Ciò era probabilmente dovuto al fatto che l’algoritmo ha utilizzato i costi sanitari storici come delega per le esigenze sanitarie — tuttavia, dal momento che il sistema sanitario degli Stati Uniti è stato storicamente afflitto da disparità di trattamento, meno denaro è stato speso per coprire le esigenze sanitarie dei pazienti neri. L’algoritmo ha quindi erroneamente concluso che sono più sani dei pazienti bianchi che sono in realtà ugualmente malati [10].
Esercizio: Se vuoi diventare tu stesso un detective dei pregiudizi, vai semplicemente su Google Traduttore (o deepl.com) e traduci dall’inglese in tedesco:
Inglese: La mia segretaria è intelligente. Ha immediatamente trovato la soluzione Google ha tentato di affrontare questo problema nel 2018 dopo una grande protesta per la traduzione in ruoli di genere stereotipati da lingue neutre di genere, ma come si può scoprire da soli, cinque anni dopo, rimangono problemi.
Panoramica dei principali rischi Click to read
Dall’uso dei robot per creare nudi falsi su Telegram, generare avatar sessualizzati di donne (ma non uomini), non sviluppare funzionalità utili a un gruppo specifico di persone, o minare l’identità di genere attraverso la classificazione binaria, le applicazioni della scienza dei dati possono causare danni. Uno dei principali rischi con l’IA e la scienza dei dati è che presumiamo che la tecnologia stessa - come ogni altro strumento - sia priva di giudizi ed errori umani. Tuttavia, in questa teoria ci sembra di dimenticare che siamo noi a creare questi sistemi, che hanno scelto gli algoritmi, che selezionano i dati e decidono come utilizzare e a chi il sistema dovrebbe essere distribuito. Pertanto, è fondamentale capire che le applicazioni della scienza dei dati - anche con le migliori intenzioni in mente - non sono né oggettive né neutrali. Rifletti su cosa può fare la tua applicazione, a cosa serve, chi è incluso/escluso e chi potrebbe essere influenzato in modi diversi - le conseguenze possono essere diffuse! Nel loro studio del 2018 [15], Joy Buolamwini e Timnit Gebru hanno scoperto che gli algoritmi di classificazione di genere che utilizzano il riconoscimento facciale di routine classificano male le donne dalla pelle scura più frequentemente degli uomini (e delle donne) con la pelle chiara. Questo perchè i set di dati su cui i modelli indagati sono stati addestrati contenevano una quota sproporzionata di immagini di uomini e donne dalla pelle chiara. ⇒ dobbiamo riconoscere che le applicazioni della scienza dei dati non sono perfette e i loro errori non sono distribuiti in modo casuale: in effetti, questi sistemi tendono a fallire più spesso per i gruppi demografici storicamente emarginati o vulnerabili. Inoltre, le applicazioni della scienza dei dati possono essere molto intense di dati, portando con sé problemi di ► Privacy: I modelli di IA che si basano su sempre più dati incentivano la raccolta di dati in diversi campi. Ciò significa che molti dati finiscono per essere raccolti sulle persone, con importanti implicazioni per la privacy. Ad esempio, mentre a volte può essere pratico dal punto di vista del consumatore sapere dove si trova esattamente il pacco al momento, e dal punto di vista di un fornitore di servizi postali può essere pratico disporre di tali dati per ottimizzare i percorsi, rintracciare il veicolo in cui viene consegnato un pacco significa anche rintracciare la persona che guida il veicolo.
► Protezione dei dati: Molti dei dati raccolti possono consentire all’utente di identificare le persone ed è quindi considerato dato di identificazione personale - come l’esempio del tracciamento dei pacchi di cui abbiamo appena discusso. Tali dati non solo possono essere utilizzati in modo improprio, ma possono anche essere utilizzati per limitare le loro opportunità, motivo per cui il regolamento generale sulla protezione dei dati dell’UE ha una politica rigorosa di minimizzazione dei dati.
► Scarsa qualità dei dati: Potresti aver sentito parlare della frase “rifiuti in entrata, rifiuti in uscita” al fine di descrivere come la scarsa qualità dei dati può portare a risultati negativi. Ciò significa che semplicemente avere un sacco di dati non renderà il tuo modello, o i tuoi risultati, migliori. Al contrario, un set di dati di grandi dimensioni, scarsamente etichettato, mal elaborato e pieno di dati irrilevanti, peggiorerà i tuoi risultati. Tieni presente: la maggior parte del tempo dedicato alla scienza dei dati e ai progetti di intelligenza artificiale è dedicato alla creazione di un set di dati di alta qualità che è quindi possibile utilizzare in modo affidabile e ripetutamente. Fai in modo che questo sforzo conti!
 Al fine di contrastare i rischi derivanti dalla scienza dei dati e dall’IA, ad oggi sono state elaborate oltre 80 diverse linee guida etiche: tra le più importanti ci sono quelle emesse da organizzazioni internazionali come l’OCSE, l’UNESCO, l’UNICEF; ma anche da grandi aziende tecnologiche, come Google e Microsoft.
Il problema di questi standard etici è che non sono né giuridicamente vincolanti, né applicabili: non ci sono conseguenze per la non conformità. Gli standard etici ci aiutano a stabilire la giusta direzione e a darci indicazioni per ciò che è sbagliato e giusto, tuttavia, il carattere volontario di tali iniziative significa che sono effettivamente un piacere da avere, invece di un deve fare.
 AI affidabile AI affidabile Click to read
In questa sezione esamineremo le caratteristiche della cosiddetta "Intelligenza Artificiale", analizzeremo da dove viene la nozione e perchè questo è importante. Ci concentreremo sul tema dei pregiudizi indesiderati che possono portare a discriminazioni e modi su come misurare l’equità con l’aiuto di una matrice di confusione. L’Unione europea ha anche creato i propri standard etici, le cosiddette "Linee guida sull’etica per un’intelligenza artificiale affidabile" [17]. Un documento elaborato dal gruppo di esperti ad alto livello sull’intelligenza artificiale (AI HLEG), un gruppo di esperti indipendente istituito dalla Commissione europea nel giugno 2018, nell’ambito della strategia dell’UE in materia di IA. L’EU HLEG ha stabilito le seguenti caratteristiche di un sistema di IA affidabile, basato sulla Carta dei diritti fondamentali dell'UE: (1) l’azione umana e la supervisione: I sistemi di IA dovrebbero essere comprensibili dagli esseri umani nella misura in cui le loro decisioni possono essere messe in discussione e gli esseri umani dovrebbero essere sempre in grado di intervenire nei sistemi di IA. Mentre la guida dell’UE HLEG va oltre i semplici orientamenti etici, fondando i principi della Carta dei diritti fondamentali dell’UE (quadro giuridico), vedremo nella prossima sezione, basata sull’esempio di equità e non discriminazione (principio 5), che c'è ancora molta strada da percorrere, dal principio all’attuazione. Pregiudizio, equità, non discriminazione Click to read
Tutti noi abbiamo il diritto umano di essere trattati in modo equo. Ma cosa si intende per equità? Fondamentalmente, l’equità è un concetto soggettivo e dipende dalla cultura e dal contesto. Nel tentativo di aggirare questo difficile problema, molta ricerca si è concentrata sulla questione dei pregiudizi nell’IA.
Tuttavia, nel contesto della scienza dei dati e dell’apprendimento automatico in generale, molte definizioni diverse di pregiudizio collidono (uso colloquiale vs Statistica vs. apprendimento profondo). Questo è un problema perchè persone provenienti da contesti disciplinari diversi parlano di pregiudizi, ma in realtà, non significano la stessa cosa. Nel contesto di un’IA affidabile, prenderemo i pregiudizi per essere un pregiudizio che favorisce un gruppo rispetto ad un altro. Tutti questi pregiudizi - nei dati, nel sistema di IA, o derivanti dall’interazione di persone pregiudizievoli con il sistema di IA - possono portare a trattamenti e discriminazioni ingiusti, il che significa il trattamento ingiusto o pregiudizievole di diverse categorie di persone, ad esempio, per motivi di etnia, età, sesso o disabilità. Ma come rilevare e misurare i pregiudizi? Il primo passo è controllare la qualità dei tuoi dati, che è uno dei modi più comuni per intrufolarsi nel set di dati. Ma anche se non ci sono difetti nei tuoi dati, il modello può ancora essere distorto. Di solito è possibile rilevare solo i pregiudizi come effetto sul risultato del modello. Lo fai con una cosiddetta Metrica di Equità, che è l’argomento della prossima sezione. Come puoi vedere, il tentativo di evitare di definire l’equità guardando invece ai pregiudizi, non è andato molto lontano.
Metrica di equità Click to read
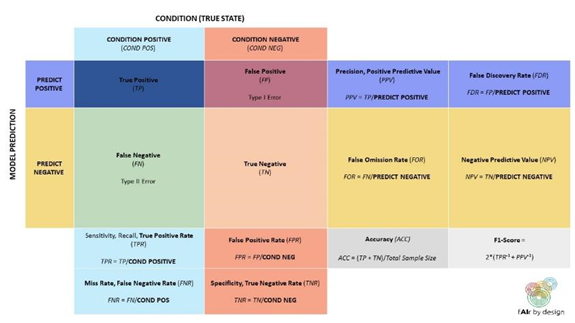
Poichè non esiste una definizione unica e perfetta di equità, non esiste una sola metrica giusta per misurare l’equità, e una soluzione unica è impossibile. Invece, ci sono molti diversi tipi di equità e modi per misurarla, tra cui l’equità di gruppo, la parità statistica condizionata, il bilanciamento del tasso di errore falso positivo, il bilanciamento del tasso di errore falso negativo, l’uguaglianza dell’accuratezza condizionale, l’uguaglianza generale dell’accuratezza, la correttezza dei test, la calibrazione, l’equità attraverso l’inconsapevolezza, l’equità controfattuale e molti altri. Sfortunatamente, non puoi semplicemente testarli per assicurarti che il tuo algoritmo sia equo, poichè queste metriche possono portare a risultati contraddittori. Ad esempio, è matematicamente impossibile soddisfare i requisiti sia per la parità predittiva che per le quote equalizzate. Considerare la seguente formula, derivata in [18]:
La p nella formula si riferisce alla prevalenza della classe POSITIVA, ed è possibile utilizzare la matrice di confusione qui sotto per capire gli altri termini. Ora supponiamo di avere due gruppi demografici, G1 e G2, con prevalenza p1 e p2. Se le quote uguali sono valide, FPR e FNR sono le stesse per entrambi i gruppi. Se la parità predittiva tiene, allora anche PPV è lo stesso per entrambi i gruppi. Collegando tutte queste informazioni nella formula sopra, finirai con due equazioni, una per G1 e una per G2. Un po’di algebra ti mostrerà che anche p1 e p2 devono essere uguali. Per riassumere: se entrambe le quote uguali e la parità predittiva sono vere, allora la prevalenza deve essere la stessa per entrambi i gruppi. Al contrario, se la prevalenza non è la stessa per entrambi i gruppi, allora le quote uguali e la parità predittiva non possono essere entrambe vere! L’impossibilità matematica di soddisfare tutte le metriche di equità contemporaneamente significa che è necessario prendere una decisione su quale definizione di equità dovrebbe essere applicata. Sfortunatamente, al momento non esiste un quadro giuridico o esempi di buone pratiche - e questo significa che è necessario considerare attentamente il contesto della tua applicazione di IA prima di scegliere la metrica per valutarne l’impatto in termini di equità. COMPAS è un sistema di intelligenza artificiale sviluppato da una società chiamata Northpointe, ed è utilizzato nel sistema di giustizia penale degli Stati Uniti al fine di stimare il rischio di recidiva di un imputato (in altre parole, per valutare il rischio di un imputato di commettere un altro crimine in futuro). Questo punteggio di rischio viene quindi utilizzato per prendere decisioni sulla libertà condizionale o sul rilascio anticipato. Nel maggio 2016, ProPublica ha pubblicato un articolo che indica che le previsioni di questo modello di modellismo recidivante erano di parte [18; Cfr. anche 19, 20]: ProPublica ha dimostrato che la formula del sistema di intelligenza artificiale era particolarmente probabile che segnalasse falsamente gli imputati neri come ad alto rischio di recidiva, etichettandoli erroneamente in questo modo a quasi il doppio del tasso degli imputati bianchi (42 % contro 22 %); allo stesso tempo, gli imputati bianchi sono stati etichettati erroneamente come a basso rischio più spesso degli imputati neri. Se guardiamo alla matrice di confusione di sopra, possiamo vedere che ProPublica stava dicendo che COMPAS era ingiusto perchè FPR e FNR non erano gli stessi per gli imputati neri rispetto agli imputati bianchi. Si scopre che questa è la metrica di equità delle quote equiparate: 1. Quote equiparate Quote equiparate significa che all’interno di ogni categoria di rischio reale, la percentuale di previsioni false negative e previsioni false positive è uguale per ogni demografia. La domanda non è più focalizzata sull’accuratezza complessiva del modello, ma piuttosto scompone i tipi di errore che il modello può fare (falsi positivi e falsi negativi), e richiede che gli errori del modello siano comparabili: FPR è uguale tra i gruppi e FNR è uguale tra i gruppi. 2. Parità predittiva La parità predittiva significa che la percentuale di imputati ad alto rischio correttamente previsti è la stessa indipendentemente dalla demografia. In altre parole, la parità predittiva si riferisce al concetto in ML e AI che i modelli predittivi utilizzati dovrebbero produrre lo stesso valore predittivo positivo (PPV) per gruppi diversi, indipendentemente dalla loro appartenenza a una classe protetta (ad esempio, razza, sesso, età, ecc.). PPV è una metrica utilizzata per valutare la proporzione di vere previsioni positive (istanze positive classificate correttamente) tra tutti i casi in cui il modello prevedeva positivo. Tuttavia, tale metrica non tiene conto della prevalenza complessiva di istanze all’interno di un set di dati! Per riformulare, la Parità Predittiva considera l’equità guardando gli errori relativi alla classe prevista, mentre le Quote equiparate esaminano gli errori relativi alla vera classe. Se è più importante ottimizzare PPV (e quindi, si preferirebbe l’equità di parità predittiva), o se si preferisce ridurre al minimo FPR (e quindi preferire quote equalizzate) è molto una questione di prospettiva. Ad esempio, quale metrica di errore è più importante per te se hai ricevuto una diagnosi medica da un sistema di IA? E quale metrica di errore è più importante in un algoritmo di assunzione utilizzato per assumere un lavoro per cui hai fatto domanda? Riesci a pensare a situazioni in cui potresti considerare il PPV più importante e altre situazioni in cui preferiresti un FPR basso? Rifletta: Tornando all’esempio COMPAS, quale definizione chiameresti giusta? Spieghiamo: È possibile soddisfare entrambe le definizioni di fair? Risposta: Dobbiamo capire la prevalenza della recidiva. Negli Stati Uniti, il tasso complessivo di recidività per gli imputati neri è superiore a quello degli imputati bianchi (52 % contro 39 %). Secondo la formula che abbiamo visto sopra, ciò significa che non è possibile che entrambe le definizioni di correttezza siano vere. Questo caso COMPAS esemplifica come le questioni sociali abbiano un impatto sui dati disponibili in primo luogo. L'eccessivo controllo di polizia delle comunità nere significa che la probabilità di arresti effettuati o incidenti registrati è più alta per queste comunità. Di conseguenza, i dati parziali vengono inseriti nei modelli. E ancora più sottile - questo significa che il tasso di recidività percepita per le due popolazioni non è lo stesso, rendendo molto difficili le decisioni su quale metrica di equità usare - cioè ciò che è anche giusto in questo contesto. Il problema reale è che ci sono pregiudizi sistemici nel sistema giudiziario e di esecuzione (negli Stati Uniti, ma anche altrove!), che non possono semplicemente essere risolti inserendo più dati (casi storici) nel sistema. Un’eccellente discussione sui problemi con l’utilizzo di dati errati per guidare previsioni nella polizia può essere trovato in “Dati Sporchi, Previsioni Sbagliate: Come le violazioni dei diritti civili impattano sui dati della polizia, sui sistemi di polizia predittiva e sulla giustizia” [22]. I pregiudizi sistemici influenzano anche altre aree di applicazione, sia che riguardino la salute, l’istruzione o il prezzo dei prodotti o servizi. A volte, possiamo scegliere gli strumenti giusti per tenere conto di tali pregiudizi sistemici. E a volte, dobbiamo ammettere che le condizioni non sono giuste per un uso sicuro degli algoritmi. Tali scelte, tuttavia, non dovrebbero essere lasciate al solo scienziato dei dati, ma dovrebbero coinvolgere una moltitudine di parti interessate e molte competenze diverse - tra cui, ad esempio, la sociologia, la psicologia, il diritto e i settori specifici del contesto.
Riassumendo Riassumendo Click to read
|





Keywords
Impatto sociale, dati per il bene, metriche di equità, monitoraggio dei social media
Objectives/goals:- Utilizzare la scienza dei dati per il bene sociale
- Comprendere i principali rischi della tecnologia ed essere in grado di citare esempi
- Essere in grado di elencare le caratteristiche di “AI affidabile”
- Comprendere le sfide della misurazione dell’equità
In questo corso, daremo un’occhiata alle molte applicazioni della scienza dei dati che possono rendere il mondo un posto leggermente migliore. Entreremo poi nel dettaglio sul monitoraggio dei social media condotto per conto di Amnesty International Italia per capire come tale applicazione può funzionare.
Nella prossima sezione, esploreremo alcuni degli effetti dannosi che la scienza dei dati e l’intelligenza artificiale possono avere. Questo ci aiuterà a capire perché è necessario che i sistemi di IA siano affidabili.
Infine, prenderemo familiarità con alcune delle sfide delle metriche di equità e vedremo cosa possono significare queste metriche nella pratica.
- [1] Skills adjacency detection and targeted training of missing skills: SkillsFuture Singapore, https://www.skillsfuture.gov.sg/AboutSkillsFuture
- [2] AI & digital twins - simulating and practicing for resilience in the supply chain: https://www.technologyreview.com/2021/10/26/1038643/ai-reinforcement-learning-digital-twins-can-solve-supply-chain-shortages-and-save-christmas/
- [3] Reducing the footprint of recycled steel: Fero Labs uses AI to help steel manufacturers reduce the use of mined ingredients by up to 34%, preventing an estimated 450,000 tons of CO2 emissions per year: https://gpai.ai/projects/responsible-ai/environment/climate-change-and-ai.pdf
- [4] Adaptive charging breaks down barriers to electric vehicle adoption. Bi-directional charging & Vehicle to Grid technologies need smart scheduling algorithms. https://ev.caltech.edu/info
- [5] Using AI to detect forced labor in the supply chain: https://www.altana.ai/blog/illuminating-xinjiang-forced-labor-ecosystem
- [6] Machine learning can boost the value of wind energy: https://www.deepmind.com/blog/machine-learning-can-boost-the-value-of-wind-energy
- [7] Barometre dell'Odio:. https://www.amnesty.it/campagne/contrasto-allhate-speech-online/
- [8] Barometre dell'Odio: Elezioni europee. https://d21zrvtkxtd6ae.cloudfront.net/public/uploads/2020/01/Amnesty-barometro-odio-2019.pdf
- [9] Barometre dell'Odio: sessimo da tastiera. https://www.amnesty.it/barometro-dellodio-sessismo-da-tastiera/#sintesi
- [10] Ziad Obermeyer et al. Dissecting racial bias in an algorithm used to manage the health of populations. https://science.sciencemag.org/content/366/6464/447
- [11] The Guardian, Amazon ditched AI recruiting tool that favored men for technical jobs, October, 2018. https://www.theguardian.com/technology/2018/oct/10/amazon-hiring-ai-gender-bias-recruiting-engine
- [12] After Google’s Gorillas comes Facebook’s Primates: Facebook Apologizes After A.I. Puts ‘Primates’ Label on Video of Black Men, September 2021. https://www.nytimes.com/2021/09/03/technology/facebook-ai-race-primates.html
- [13]
- [14]
- [15] Joy Buolamwini & Timnit Gebru. Gender Shades: Intersectional Accuracy Disparities in
Commercial Gender Classification. http://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf - [16] The algorithms that detect hate speech online are biased against Black people. August 2019. https://www.vox.com/recode/2019/8/15/20806384/social-media-hate-speech-bias-black-african-american-facebook-twitter
- [17] EU HLEG Guidelines for trustworthy AI: https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai
- [18] Chouldechova A. Fair Prediction with Disparate Impact: A Study of Bias in Recidivism Prediction Instruments. Big Data. 2017 Jun;5(2):153-163.
- [19] Machine bias. There's software used across the country to predict future criminals. And it's biased against blacks. May 2016. https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
- [20] A computer program used for bail and sentencing decisions was labeled biased against blacks. It’s actually not that clear. October 2016. https://www.washingtonpost.com/news/monkey-cage/wp/2016/10/17/can-an-algorithm-be-racist-our-analysis-is-more-cautious-than-propublicas/
- [21] Julia Dressl and Hany Farid. The accuracy, fairness, and limits of predicting recidivism. January 2018. https://www.science.org/doi/10.1126/sciadv.aao5580
- [22] Sahil Verma, Julia Rubin: „Fairness Definitions Explained”, 2018 ACM/IEEE International Workshop on Software Fairness; https://dl.acm.org/doi/10.1145/3194770.3194776
Related training material






