DataScience Training
 Redare audio
Redare audio




|
Data Science & Impactul Social: Obținerea rezultatelor pozitive Introducere Obținerea rezultatelor pozitive Click to read
 Data Science și AI au o mare varietate de aplicații cu impact social pozitiv. De exemplu, data science este utilă pentru a investiga modul în care rețelele sociale influențează drepturile omului. Pe de altă parte, data science și aplicațiile AI implică, de asemenea, riscuri pentru sănătate, siguranță, mediu și drepturile omului. Prejudecățile și discriminarea, preocupările legate de confidențialitate și efectele nocive asupra mediului sunt doar câteva dintre efectele posibile. Pentru a ne asigura că aplicațiile de data science aduc beneficii oamenilor și planetei, este necesar să se înțeleagă atât capacitățile, cât și riscurile acestora. În acest curs, vor fi introduse ambele aspecte și, de asemenea, vor fi introduse și unele metode de adresare a riscurilor. Utilizarea data science pentru binele social Prezentare generală a cazurilor în care se poate utiliza data science pentru binele general Click to read
Exemple din industrie • Detectarea adiacenței abilităților și formarea țintită a abilităților lipsă: SkillsFuture Singapore, https://www.skillsfuture.gov.sg/AboutSkillsFuture
• AI & digital twins - simulating and practicing for resilience in the supply chain: https://www.technologyreview.com/2021/10/26/1038643/ai-reinforcement-learning-digital-twins-can-solve-supply-chain-shortages-and-save-christmas/
• Reducerea amprentei de carbon a oțelului reciclat: Fero Labs folosește inteligența artificială pentru a ajuta producătorii de oțel să reducă utilizarea ingredientelor extrase cu până la 34%, prevenind producerea a aproximativ 450.000 de tone de emisii de CO2 pe an: https://gpai.ai/projects/responsible-ai/environment/climate-change-and-ai.pdf
• Încărcarea adaptivă înlătură barierele în calea adoptării vehiculelor electrice. Încărcarea bi-direcționala și tehnologiile ”de la vehicul la rețea” au nevoie de algoritmi de programare inteligenți. https://ev.caltech.edu/info
• Utilizarea AI pentru a detecta munca forțată în lanțul de aprovizionare: https://www.altana.ai/blog/illuminating-xinjiang-forced-labor-ecosystem • Utilizarea Machine learning poate crește valoarea energiei eoliene: https://www.deepmind.com/blog/machine-learning-can-boost-the-value-of-wind-energy
Cazul Amnesty Italy Click to read
Barometro dell‘Odio: Monitorizare anuală a campaniilor Social Media din 2018. Care este tonul discursului online, în special al discuțiilor politice și legate de drepturile omului? În ce măsură intoleranța și discriminarea modelează peisajul rețelelor sociale și care este impactul asupra grupurilor dezavantajate? Data Science în serviciul evaluării impactului asupra drepturilor omului. Modalități: ØConținut public descărcat via Twitter și Facebook, prin intermediul API
ØColectat dintr-o listă de conturi/profiluri publice determinate de Amnesty Italy
ØMonitorizare de 4-8 săptămâni (excepție: 2021 cu 16 săptămâni de monitorizare)
ØEșationare aleatorie a comentariilor din cele mai active conturi
Ø Între 30.000 și 100.000 de comentarii selectate în acest mod
ØEtichetare manuală de către 50 – 150 voluntari pregătiți Amnesty: subiect și gradul caracterului ofensator
ØVerificare încrucișată (același comentariu etichetat de 2-3 voluntari) a tuturor comentariilor
Ø Rezolvarea etichetărilor inconsistente și determinarea țintei și a tipului de ofensă - de către experții Amnesty („Tavolo dell‘Odio“)
Exemplu: Alegerile Parlamentare Europene 2019 Au fost monitorizate profilurile publice de Twitter și Facebook a 461 de candidați, plus liderii de partid. Ø6 săptămâni (din 15 Aprilie până la 24 Mai, 2019)
ØPeste 27 de mii de postări și 4 milioane de comentarii au fost colectate
ØAvând în vedere volumul mare de comentarii, a trebuit să se facă o selecție a feed-urilor politicienilor care să fie evaluate. Criteriile au fost: amploarea activității pe rețelele de socializare, asigurând în același timp o reprezentare a tuturor partidelor, a tuturor regiunilor și a cel puțin o femeie/bărbat per partid. Ca urmare, au fost evaluate feed-urile a 77 de politicieni.
Ø80% din postări și o eșantionare aleatorie de 100 de mii de comentarii au fost etichetate de 150 de voluntari Amnesty
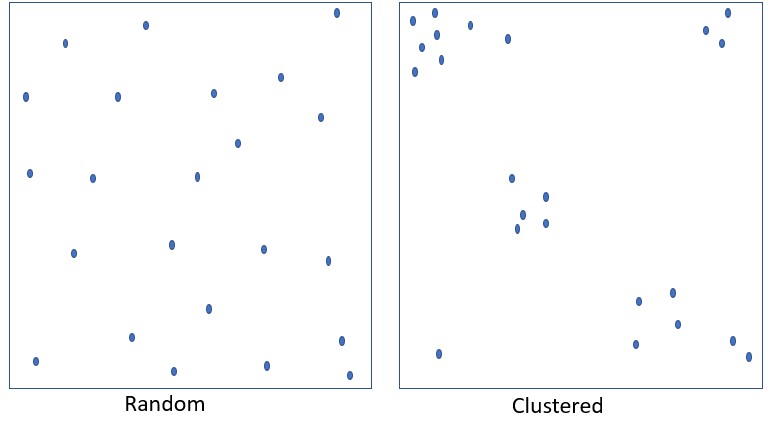
Discursul de Ură nu este distribuit aleator: Fiecare dreptunghi are exact același număr și dimensiune a punctelor albastre
Conform datelor Amnesty Italia, prevalența discursului de ură este de aproximativ 1%. Dar tinde să se concentreze asupra anumitor grupuri și subiecte. De asemenea, are vârfuri de concentrare în anumite perioade.
Topicuri ”fierbinți”: Migrație/Refugiați/Azilanți; Roma; Minorități religioase; Femei și drepturile femeilor, ... Discursul ofensator este: ØUn catalizator pentru și mai mult discurs ofensator
ØMai popular: în medie, postările ofensatoare atrag mai multe interacțiuni – distribuiri, reacții, răspunsuri
ØUn obstacol pentru libertatea de expresie: în timpul perioadei de monitorizare (Noiembrie – Decembrie 2019) pentru ediția„Sessismo da Tastiera“, s-a observat că trei femei au fost țintă și două femei au fost înlăturate de pe platformele social medie prin campanii de ură.
Øhttps://www.amnesty.it/barometro-dellodio-sessismo-da-tastiera/#sintesi
ØReport, p.20
Data science nu face întotdeauna bine Exemple majore cunoscute Click to read
Prejudecată, discriminare, stereotipuri … ØZiad Obermeyer et al. Dissecting racial bias in an algorithm used to manage the health of populations. https://science.sciencemag.org/content/366/6464/447
ØThe Guardian, Amazon a renunțat la instrumentul de recrutare AI care favoriza bărbații pentru joburi tehnice, Octombrie, 2018.
https://www.theguardian.com/technology/2018/oct/10/amazon-hiring-ai-gender-bias-recruiting-engine ØDupă Gorilele Google vin Primatele Facebook: Facebook își cere scuze după ce AI eticheteaza drept ”Primate” videoclipuri cu bărbați de culoare, Septembrie 2021. https://www.nytimes.com/2021/09/03/technology/facebook-ai-race-primates.html
Prejudecată, discriminare, stereotipuri … muncă, și mediu
ØSemuels, A., Internetul permite un nou tip de ias prost plătit, în The Atlantic, 23 Ianuarie, 2018.
https://www.theatlantic.com/business/archive/2018/01/amazon-mechanical-turk/551192/
ØGeiger, G., Curtea decide Deliveroo a folosit un algoritm ‘Discriminatoriu’, Motherboard, Ianuarie 2021.
https://www.vice.com/en/article/7k9e4e/court-rules-deliveroo-used-discriminatory-algorithm
ØHao, K., Antrenarea unui singur model AI poate emite la fel de mult carbon cât cinci mașini în timpul vieții lor, în MIT Technology Review, 6 Iunie, 2019
https://www.technologyreview.com/s/613630/training-a-single-ai-model-can-emit-as-much-carbon-as-five-cars-in-their-lifetimes/
Fii un detectiv de imparțialitate
Da, poți încerca acest experiment acasă!*
Introdu următorul text în Google Translate și tradu din Engleză în Germană: Engleză: My doctor is clever. She immediately found the solution Google Germană:
Engleză: My secretary is clever. He immediately found the solution Google Germană: *Hat tip Liad Magen pentru idee
Prezentare generală a principalelor riscuri Click to read
Aplicațiile Data science nu sunt nici obiective, nici neutre: De la utilizarea roboților pentru a crea nuduri deepfake nudes peTelegram, generarea de avatare sexualizate ale femeilor (dar nu ale bărbaților), nedezvoltarea de funcționalități utile unui anumit grup de persoane sau subminarea identității de gen prin clasificare binară, aplicațiile Data Science pot provoca daune. ØReflectați la ce poate face aplicația dvs., pentru ce este utilizată, cine este inclus/exclus și cine ar putea fi afectat în moduri diferite - consecințele pot avea multiple ramificații!
Aplicațiile date science nu sunt perfecte și erorile lor nu sunt distribuite aleator:
În plus, aplicațiile Data Science pot consuma foarte mult date, implicând diferite probleme: ØConfidențialitate
ØProtecția datelor
ØCalitate slabă a datelor (”garbage in, garbage out”)
 Etică – Ghiduri
•Microsoft AETHER: https://www.microsoft.com/en-us/ai/responsible-ai
•Google fostul Comitet de etică: https://www.reuters.com/article/us-alphabet-google-ai-idUSKCN1RH00S
•Partnership on AI: https://www.partnershiponai.org/
•... Peste 80 de ghiduri de etică sunt disponibile astăzi
Etică – Ghiduri
Frumos, dar să discutăm când devin obligatorii...
Trustworthy AI AI de încredere Click to read
HLEG UE a stabilit următoarele caracteristici ale unui sistem de AI de încredere, bazat pe Carta drepturilor fundamentale a UE: (2) robustețe tehnică și siguranță, (3) confidențialitate și guvernanța datelor, (4) transparență, (5) diversitate, nediscriminare și corectitudine, (6) bunăstarea mediului și a societății și (7) responsabilitate
Prejudecăți, echitate, nediscriminare Click to read
ØCe este prejudecata (bias)?
în contextul Data Science și al învățării automate în general, multe definiții diferite ale părtinirii se întâlnesc și se pot contrazice (utilizare colocvială vs. Statistică vs. Deep Learning) ØCe este echitatea?
Prejudecată socială Prejudecată de confirmare Prejudecată de grup Prejudecată automată Prejudecată temporală Denaturare determinată de variabile omise Erori de eșantionare (sampling bias) Erori de reprezentare Erori de măsurare Erori de evaluare ... Și altele ...
Cum poate fi detectată și măsurată părtinirea? Primul pas, verificarea calității datelor. Și apoi ...
... De fapt, se poate detecta doar ca efect asupra rezultatelor modelului Prin măsurare cu o Metrică de Echitate!
Metrici de echitate Click to read
Corectitudinea grupului Paritate statistică condiționată Rata de eroare fals pozitivă Rata de eroare fals negativă Rata de acuratețe a utilizării condiționate Rata de acuratețe generală Corectitudinea testelor Calibrarea corectă Echitate prin neconștientizare Corectitudine contrafactuală ... Și multe altele ...
Proporția de riscuri ridicate prezise corect este aceeași, indiferent de criteriile demografice Paritate predictivă (Toate grupurile au aceeași PPV) În cadrul fiecărei categorii de risc real, procentul de predicții false este egal pentru fiecare grup demografic
Cote egalizate (Toate grupurile au același FNR și același FPR)
Ce definiție ai spune că este echitabilă? Ce se întâmplă când prevalența riscului ridicat este mai mare pentru un grup decât pentru altul? Dacă p este proporția indivizilor cu risc ridicat în populație: .... Atunci această formula ne spune că nu putem avea atât cote egalizate, cât și paritate predictivă Pentru a înțelege de ce, să presupunem că atât cotele egalizate, cât și paritatea predictivă sunt adevărate. Introduceți în formulă și câteva elemente de algebră vă vor arăta că atunci prevalența p ar trebui să fie aceeași pentru ambele populații ... Să ne amintim un exemplu larg dezbătut: În mai 2016, ProPublica a publicat un articol care indica faptul că predicțiile realizate de un model larg răspândit pentru recidivism (COMPAS), erau părtinitoare: •Julia Dressel and Hany Farid, The accuracy, fairness, and limits of predicting recidivism, Science Advances, 17 Jan 2018: Vol. 4, no. 1. https://advances.sciencemag.org/content/4/1/eaao5580.full https://advances.sciencemag.org/content/4/1/eaao5580.full
 PARITATE PREDICTIVĂ Proporția cazurilor cu risc ridicat previzionate corect este aceeași indiferent de grupul demografic
Toate grupurile au același PPV
Northpointe spune... este echitabil, deoarce în fiecare categorie de risc, proporția inculapaților care recidivează este aproximativ aceeași indiferent de rasă
COTE EGALIZATE Toate grupurile au FNR și FPR egale ProPublica spune … nu este echitabil, deoarece în cazul inculpaților care în cele din urmă nu au recidivat, cei de culoare au fost de două ori mai probabil decât cei albi să fie clasificați cu risc mediu sau ridicat (42% vs. 22%)
Rata generală de recidivă pentru inculpații de culoare este mai mare decât cea pentru inculpații albi (52 de procente vs. 39 de procente) Rata de recidivă generală pentru inculpații de culoare este mai mare decât pentru cei albi (52 procente vs. 39 de procente) Problema ... Rata generală de recidivă pentru inculpații de culoare este mai mare decât pentru inculpații albi (52 procente vs. 39 procente) ... Este prejudecata sistemică Poate fi periculos să implementezi sisteme automatizate pentru a lua sau a sprijini decizii în contexte sociale în care prejudecățile sunt profund înrădăcinate. Implicarea diferitelor părți interesate și a experților din diferite domenii, în decizia privind metrica de echitate utilizată este una vitală. Și, în sfârșit, rețineți că, uneori, data science ar putea să nu fie abordarea potrivită... |



Keywords
Impact Social, Date pentru binele general, metrici de echitate, monitorizarea social media
Objectives/goals:1. Utilizarea data science pentru binele social
2. Înțelegerea principalelor riscuri ale tehnologiei și identificarea exemplelor
3. Să fiți capabili să enumerați caracteristicile ”AI de încredere”
4. Să înțelegeți provocările măsurării echității
În acest curs, vom arunca o privire asupra numeroaselor aplicații ale Data Science care pot face lumea un loc mai bun. Vom intra apoi în detaliu asupra monitorizării rețelelor sociale efectuate în numele Amnesty International Italia, pentru a înțelege cum poate funcționa o astfel de aplicație.
În secțiunea următoare, vom explora unele dintre efectele dăunătoare pe care le pot avea Data Science și AI (Inteligența Artificială). Acest lucru ne va ajuta să înțelegem de ce este nevoie ca sistemele AI să fie de încredere.
În cele din urmă, ne vom familiariza cu unele dintre provocările măsurătorilor sau metricilor de echitate și vom vedea ce pot însemna aceste metrici în practică.
- [1] Skills adjacency detection and targeted training of missing skills: SkillsFuture Singapore, https://www.skillsfuture.gov.sg/AboutSkillsFuture
- [2] AI & digital twins - simulating and practicing for resilience in the supply chain: https://www.technologyreview.com/2021/10/26/1038643/ai-reinforcement-learning-digital-twins-can-solve-supply-chain-shortages-and-save-christmas/
- [3] Reducing the footprint of recycled steel: Fero Labs uses AI to help steel manufacturers reduce the use of mined ingredients by up to 34%, preventing an estimated 450,000 tons of CO2 emissions per year: https://gpai.ai/projects/responsible-ai/environment/climate-change-and-ai.pdf
- [4] Adaptive charging breaks down barriers to electric vehicle adoption. Bi-directional charging & Vehicle to Grid technologies need smart scheduling algorithms. https://ev.caltech.edu/info
- [5] Using AI to detect forced labor in the supply chain: https://www.altana.ai/blog/illuminating-xinjiang-forced-labor-ecosystem
- [6] Machine learning can boost the value of wind energy: https://www.deepmind.com/blog/machine-learning-can-boost-the-value-of-wind-energy
- [7] Barometre dell'Odio:. https://www.amnesty.it/campagne/contrasto-allhate-speech-online/
- [8] Barometre dell'Odio: Elezioni europee. https://d21zrvtkxtd6ae.cloudfront.net/public/uploads/2020/01/Amnesty-barometro-odio-2019.pdf
- [9] Barometre dell'Odio: sessimo da tastiera. https://www.amnesty.it/barometro-dellodio-sessismo-da-tastiera/#sintesi
- [10] Ziad Obermeyer et al. Dissecting racial bias in an algorithm used to manage the health of populations. https://science.sciencemag.org/content/366/6464/447
- [11] The Guardian, Amazon ditched AI recruiting tool that favored men for technical jobs, October, 2018. https://www.theguardian.com/technology/2018/oct/10/amazon-hiring-ai-gender-bias-recruiting-engine
- [12] After Google’s Gorillas comes Facebook’s Primates: Facebook Apologizes After A.I. Puts ‘Primates’ Label on Video of Black Men, September 2021. https://www.nytimes.com/2021/09/03/technology/facebook-ai-race-primates.html
- [13]
- [14]
- [15] Joy Buolamwini & Timnit Gebru. Gender Shades: Intersectional Accuracy Disparities in
Commercial Gender Classification. http://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf - [16] The algorithms that detect hate speech online are biased against Black people. August 2019. https://www.vox.com/recode/2019/8/15/20806384/social-media-hate-speech-bias-black-african-american-facebook-twitter
- [17] EU HLEG Guidelines for trustworthy AI: https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai
- [18] Chouldechova A. Fair Prediction with Disparate Impact: A Study of Bias in Recidivism Prediction Instruments. Big Data. 2017 Jun;5(2):153-163.
- [19] Machine bias. There's software used across the country to predict future criminals. And it's biased against blacks. May 2016. https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
- [20] A computer program used for bail and sentencing decisions was labeled biased against blacks. It’s actually not that clear. October 2016. https://www.washingtonpost.com/news/monkey-cage/wp/2016/10/17/can-an-algorithm-be-racist-our-analysis-is-more-cautious-than-propublicas/
- [21] Julia Dressl and Hany Farid. The accuracy, fairness, and limits of predicting recidivism. January 2018. https://www.science.org/doi/10.1126/sciadv.aao5580
- [22] Sahil Verma, Julia Rubin: „Fairness Definitions Explained”, 2018 ACM/IEEE International Workshop on Software Fairness; https://dl.acm.org/doi/10.1145/3194770.3194776
Related training material






