|
Text Mining
Introducción
¿Qué es la extracción de textos? Click to read 
•La extracción de textos es una confluencia del procesamiento del lenguaje natural, la extracción de datos, el aprendizaje automático y la estadística utilizada para extraer conocimientos de textos no estructurados.
•En términos generales, la extracción de textos puede clasificarse en dos tipos:
ØLas preguntas del usuario son muy claras y específicas, pero no conoce la respuesta a las mismas.
ØEl usuario sólo conoce el objetivo general, pero no tiene preguntas concretas y definidas.
Retos de la extracción de textos Click to read
•El texto en lenguaje natural no está estructurado.
•La mayoría de los métodos de extracción de datos manejan datos estructurados o semiestructurados=> el análisis y modelado de texto de lenguaje natural no estructurado es todo un reto.
•La extracción de datos de texto es de hecho una tecnología integrada de procesamiento del lenguaje natural, clasificación de patrones y aprendizaje automático.
•El sistema teórico del procesamiento del lenguaje natural aún no se ha establecido por completo.
•Las principales dificultades a las que se enfrenta la extracción de textos vienen generadas por
ØLa aparición de ruido o expresiones mal formadas
ØExpresiones ambiguas en el texto
ØDifícil recopilación y anotación de muestras para nutrir los métodos de aprendizaje automático
ØDificultad para expresar el propósito y los requisitos de la extracción de textos.
Flujo del proceso de extracción de datos Click to read
•La extracción de textos realiza algunas tareas generales para extraer de forma eficaz textos, documentos, libros, comentarios:
Técnicas de extracción de textos
Técnicas tipicas de extracción de textos Click to read
La extracción de textos es un campo de investigación en el que confluyen múltiples tecnologías y técnicas:
ØLos métodos de clasificación de textos dividen un texto dado en tipos de texto predefinidos.
ØLas técnicas de agrupación de textos dividen un texto dado en diferentes categorías.
ØModelos temáticos = modelos estadísticos utilizados para extraer los temas y conceptos ocultos tras las palabras de un texto.
ØAnálisis de sentimiento de texto (extracción de opiniones de texto) revela la información subjetiva expresada por el autor de un texto, es decir, el punto de vista y la actitud del autor. El texto se clasifica en función de las actitudes expresadas en él o de los juicios sobre su polaridad positiva o negativa.
Ø El análisis del sentimiento textual (extracción de opiniones de texto) revela la información subjetiva expresada por el autor de un texto, es decir, el punto de vista y la actitud del autor. El texto se clasifica en función de las actitudes expresadas en él o de los juicios sobre su polaridad positiva o negativa.
ØLa detección de temas se refiere a la extracción y selección de temas de texto (temas candentes) fiables para el análisis de la opinión pública, la informática de medios sociales y los servicios de información personalizados.
ØLa extracción de información se refiere a la extracción de información factual, como entidades, atributos de entidades, relaciones entre entidades y eventos, a partir de texto de lenguaje natural no estructurado y semiestructurado, que forma en la salida de datos estructurados.
ØEl resumen automático de texto genera resúmenes automáticamente utilizando métodos de procesamiento del lenguaje natural.
Técnicas de preparación y transformación de datos Click to read
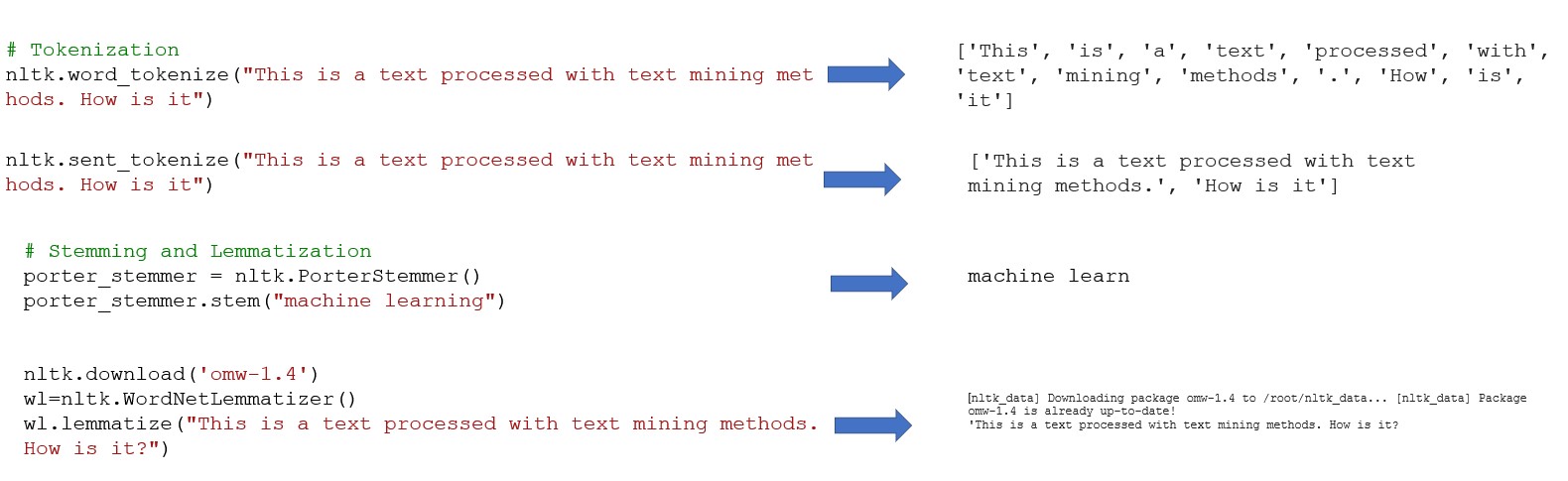
•La tokenización consiste en segmentar un texto en unidades léxicas
•Eliminación de palabras vacías: Se trata principalmente de palabras funcionales, como palabras auxiliares, preposiciones, conjunciones, palabras modales y otras palabras de alta frecuencia.
•Normalización de la forma de las palabras para mejorar la eficacia del tratamiento de textos. La normalización de la forma de las palabras incluye dos conceptos básicos:
ØLematización: restauración de palabras deformadas a su forma original para expresar la semántica completa,
ØStemming - El proceso de eliminación de afijos para obtener raíces.
•La anotación de datos representa una etapa esencial de los métodos de aprendizaje automático supervisado. Si la escala de datos anotados es mayor, la calidad es más alta, y si la cobertura es más amplia, el rendimiento del modelo entrenado será mejor
Conceptos básicos de la representación de textos Click to read
El modelo de espacio vectorial es el método de representación de texto más sencillo
•Conceptos básicos relacionados:
ØTexto es una secuencia de caracteres con cierta granularidad, como frases, oraciones, párrafos o un documento completo.
ØTérmino es la Unidad lingüística inseparable más pequeña que puede denotar caracteres, palabras, frases, etc
ØEl peso del término es el peso asignado a un término según ciertos principios, que indica la importancia y relevancia de ese término en el texto.
•El modelo de espacio vectorial supone que un texto cumple los dos requisitos siguientes: (1) cada término es único, (2) los términos no tienen orden.
•El objetivo del aprendizaje profundo para la representación de texto es aprender vectores densos de baja dimensión de texto en diferentes granularidades a través del aprendizaje automático.
•El modelo de bolsa de palabras es el método de representación de texto más popular en tareas de extracción de datos de texto como la clasificación de textos y el análisis de sentimientos.
Representación de texto
•El objetivo de la representación de textos es construir una buena representación adecuada para tareas específicas de procesamiento del lenguaje natural:
ØPara la tarea de análisis de sentimientos, es necesario incorporar más atributos emocionales,
ØPara las tareas de detección y seguimiento de temas, es necesario incorporar más información de descripción de eventos.
Clasificación de texto Click to read
Clasificación de texto
•En la clasificación de textos, un documento debe representarse correcta y eficazmente para los algoritmos de clasificación.
•La selección de un método de representación del texto depende de la elección del algoritmo de clasificación.
Algoritmos básicos de aprendizaje automático para la clasificación de textos
•Text classification algorithms:
ØNaive Bayes es un conjunto de clasificadores que funciona según los principios del teorema de Bayes. Naive Bayes modela la distribución conjunta p(x, y) de la observación x y su clase y.
ØLa máxima entropía (ME) asigna la probabilidad conjunta a los pares de observación y etiqueta (x, y) basándose en un modelo log-lineal :
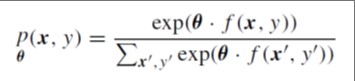 |
donde: θ es un vector de pesos, f es una función que asigna pares (x, y) a un vector de características de valor binario
|
ØLas máquinas de vectores soporte (SVM) son un algoritmo de aprendizaje discriminativo supervisado para la clasificación binaria.
ØLos métodos ensemble combinan múltiples algoritmos de aprendizaje para obtener un mejor rendimiento predictivo que cualquiera de los algoritmos de aprendizaje base por sí solos.
Introducción en modelos temáticos y BERT Click to read
Introducción en modelos temáticos
•Los modelos temáticos proporcionan un método de representación de conceptos que transforma los vectores dispersos de alta dimensión del modelo tradicional de espacio vectorial en vectores densos de baja dimensión para paliar la maldición de la dimensionalidad. Pueden captar mejor la polisemia y la sinonimia y extraer temas implícitos (también llamados conceptos) en los textos.
•Modelos temáticos básicos:
ØEl Análisis Semántico Latente (LSA) representa un fragmento de texto mediante un conjunto de conceptos semánticos implícitos en lugar de los términos explícitos del modelo de espacio vectorial. El LSA reduce la dimensión de la representación del texto seleccionando temas latentes en lugar de términos explícitos como base para la representación del texto mediante la siguiente matriz de descomposición:
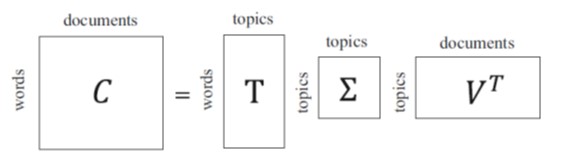
ØEl análisis semántico latente probabilístico (PLSA) amplía el marco para incluir la probabilidad.
ØLa asignación de Dirichlet latente (LDA) introduce una distribución de Dirichlet en la distribución temática condicional del documento y en la distribución temática condicional del término.
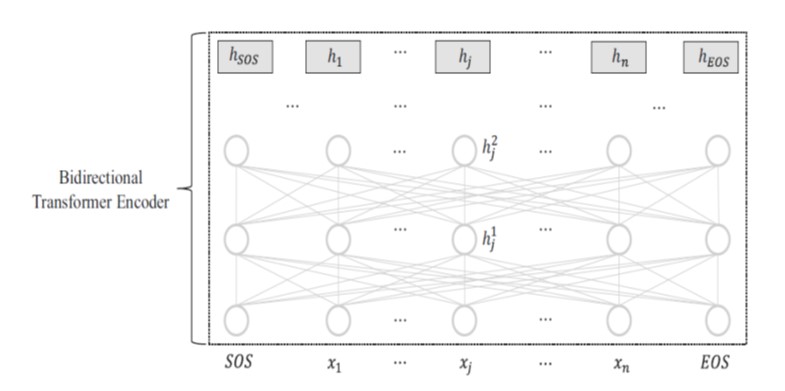
BERT: Representaciones bidireccionales del codificador a partir del transformador
•BERT es un modelo de preentrenamiento y ajuste fino que emplea el codificador bidireccional de Transformer
•La representación de cada token de entrada hj se aprende atendiendo tanto al contexto del lado izquierdo, x1, · · · , xj−1 como al contexto del lado derecho xj+1, · · · , xn.
•Los contextos bidireccionales son cruciales en tareas como el etiquetado secuencial y la respuesta a preguntas.
•Las aportaciones de BERT:
ØBERT emplea un modelo mucho más profundo que GPT, y el codificador bidireccional consta de hasta 24 capas con 340 millones de parámetros de red.
ØBERT diseña dos funciones objetivo no supervisadas, que incluyen el modelo de lenguaje enmascarado y la predicción de la siguiente frase.
ØBERT se entrena previamente en conjuntos de datos de texto aún mayores.
Análisis de sentimientos y extracción de opiniones Click to read
•Las principales tareas del análisis de sentimientos y la extracción de opiniones incluyen la extracción, clasificación e inferencia de información subjetiva en textos, como sentimiento, opinión, actitud, emoción, postura.
•Las técnicas de análisis de sentimientos se dividen naturalmente en dos categorías:
ØMétodos basados en reglas: realizan el análisis del sentimiento en distintas granularidades del texto basándose en la orientación del sentimiento de las palabras proporcionada por un léxico del sentimiento,
ØMétodos basados en el aprendizaje automático: se centran en la ingeniería eficaz de características para la representación del texto y el aprendizaje automático.
Caso de estudio con Python
Bibliotecas comunes de Python para extracción de textos Click to read
Bibliotecas comunes de Python para extracción de textos
ØNLTK (Natural Language Toolkit) - incluye potentes bibliotecas para el procesamiento simbólico y estadístico del lenguaje natural que pueden funcionar con diferentes técnicas de ML
ØSpaCy - biblioteca de código abierto para PLN en Python diseñada para la extracción de información o el procesamiento del lenguaje natural con fines generales
ØTextBlob Library proporciona una API sencilla para tareas de PLN como el etiquetado de parte del habla, la extracción de frases nominales, el análisis de sentimientos, la clasificación, la traducción, etc.
ØStanford NLP contiene herramientas útiles para convertir una cadena de texto en lenguaje humano en listas de frases y palabras, generar formas base de esas palabras, sus partes de la oración y características morfológicas, y proporcionar un análisis sintáctico de dependencia de la estructura, diseñado para ser paralelo en más de 70 idiomas.
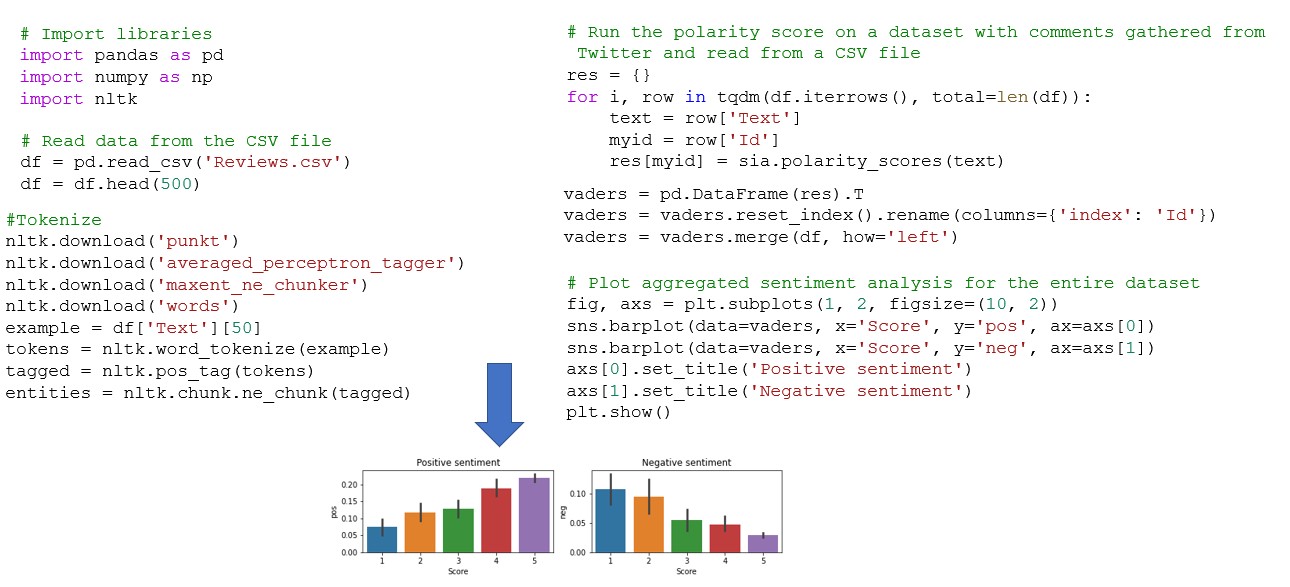
Uso de las bibliotecas NTLK para la extracción de textos Click to read Ejemplo de análisis de sentimientos mediante el método de la bolsa de palabras y la biblioteca NLTK Click to read Clasificación de textos utilizando la base Naive Click to read
Predict the sentiment of a given review using a Naïve Bayse machine learning model

|
 Reproducir el audio
Reproducir el audio