DataScience Training
 Reproducir el audio
Reproducir el audio 







Keywords
Unidades estadísticas, clúster, intraclúster, interclúster, índice de disimilitud, distancia de fusión, dendograma
Objectives/goals:El objetivo de este módulo es introducir y explicar la técnica del Análisis Cluster.
Al finalizar este módulo serás capaz de:
Conocer la lógica del Análisis Cluster
Conocer los requisitos
Realizar un Análisis Cluster
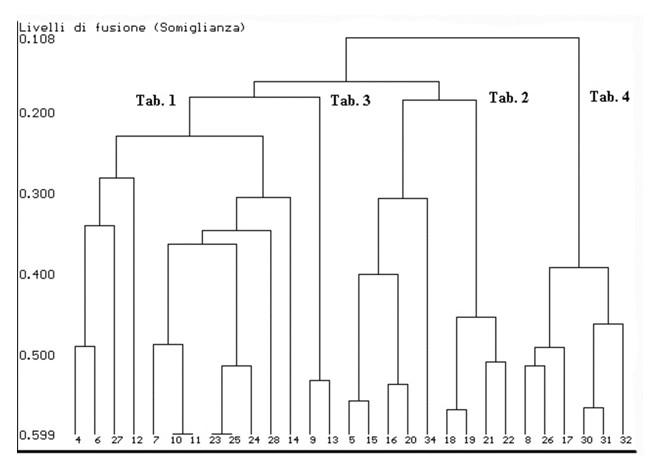
En este módulo de formación se te presentará la técnica de análisis multidimensional denominada Análisis de clústeres, también llamada análisis automático de grupos.
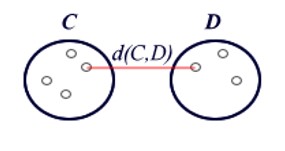
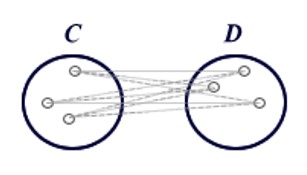
Los análisis de clústeres se utilizan para agrupar unidades estadísticas que tienen características en común y asignarlas a categorías no definidas a priori. Los grupos que se forman deben ser lo más homogéneos posible en su interior (intracluster) y heterogéneos en su exterior (intercluster).
Las aplicaciones de este tipo de análisis son múltiples: informática, medicina, biología, marketing.
La última parte del módulo se dedicará a la aplicación del análisis cluster con el software R.
Related training material






