DataScience Training
 Reproducir el audio
Reproducir el audio 





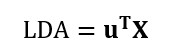
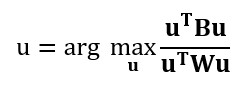


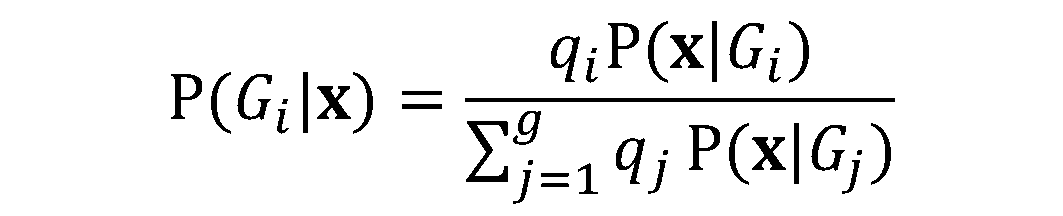
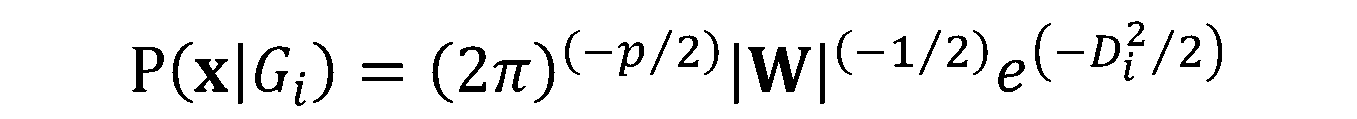




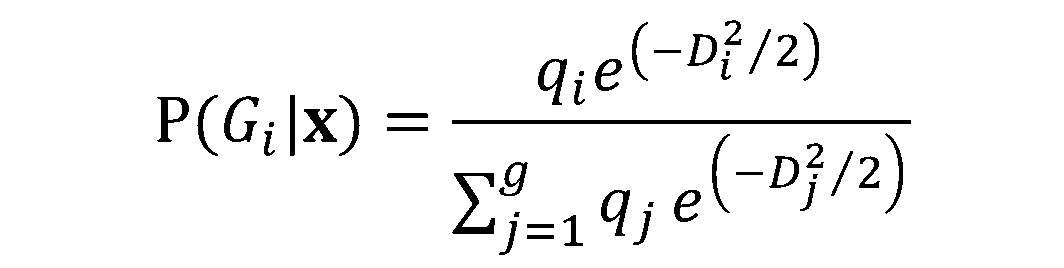



Keywords
análisis discriminante, clasificación, R, análisis bayesiano
Objectives/goals:El objetivo de este módulo es introducir y explicar los fundamentos del Análisis Discriminante Lineal (LDA).
Al finalizar este módulo será capaz de:
Identificar situaciones en las que el LDA puede ser útil
Calcular funciones LDA
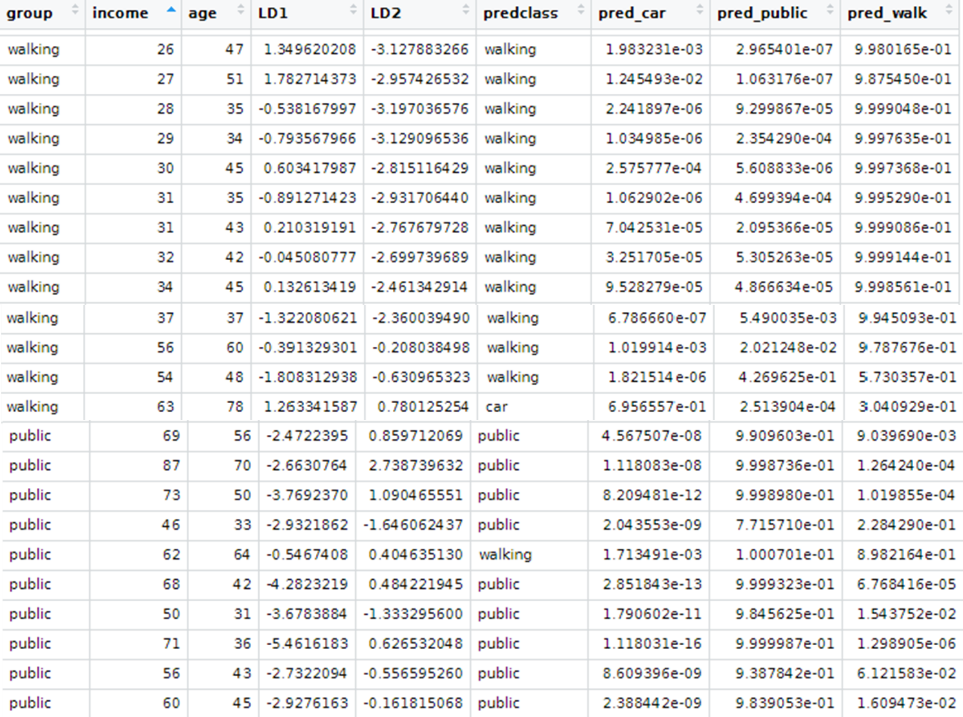
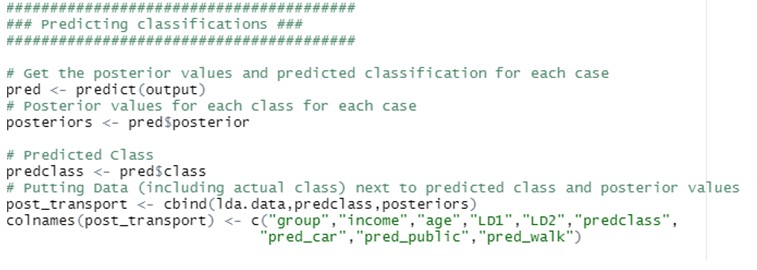
Interpretar los resultados producidos por LDA descriptivo y predictivo
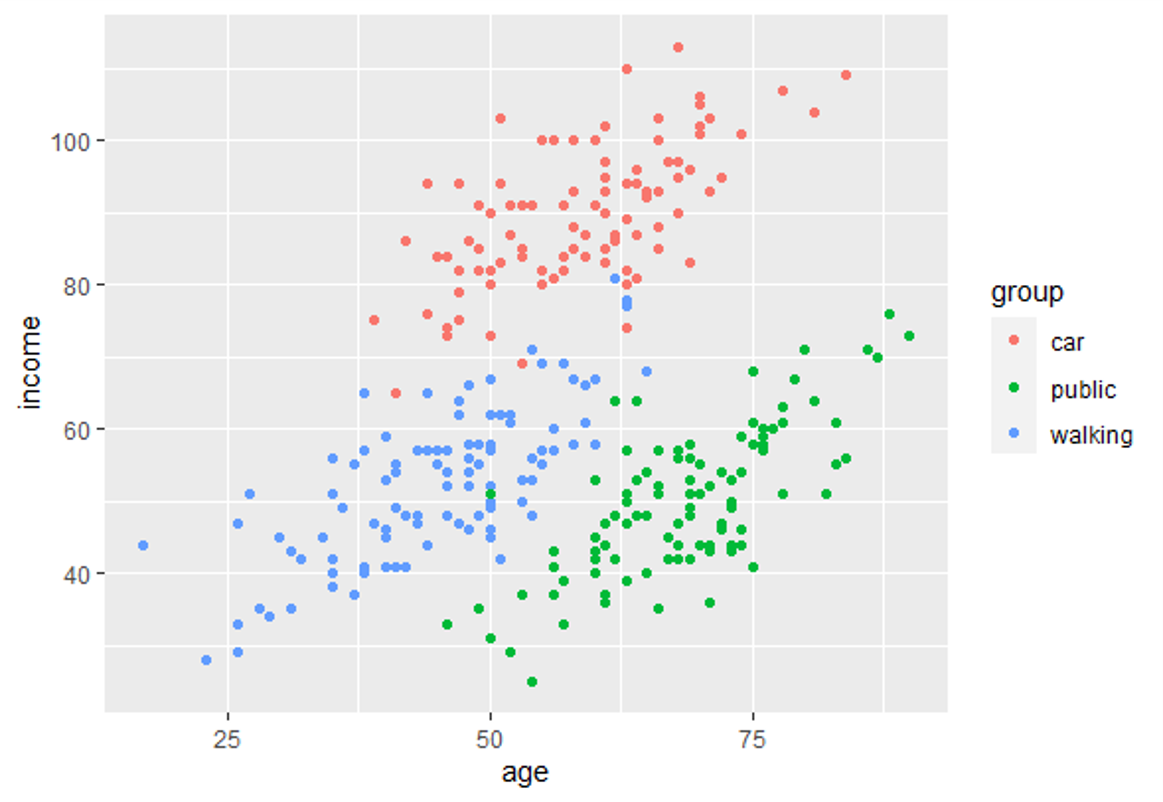
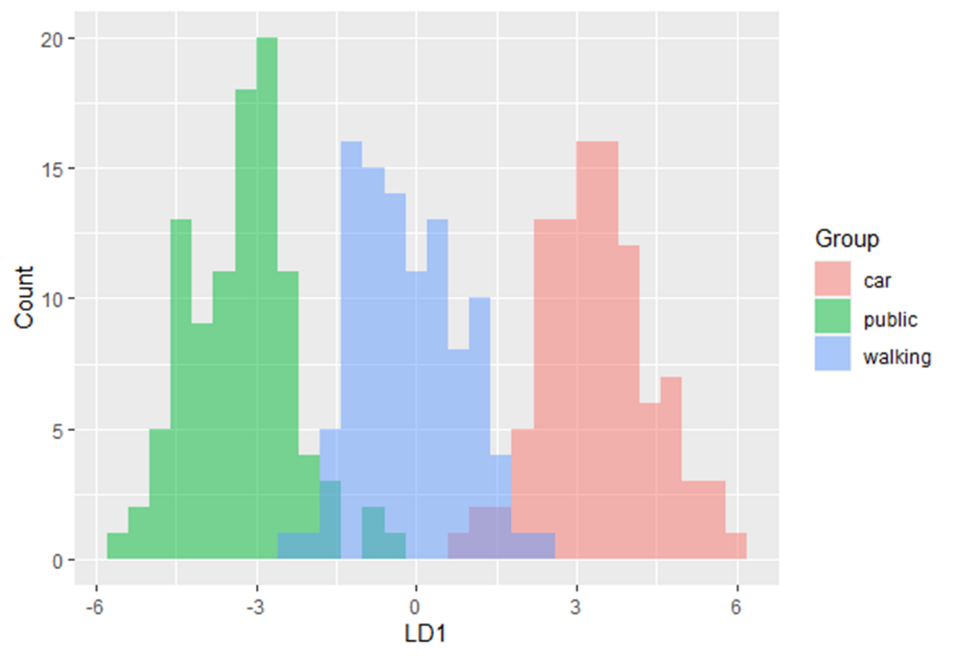
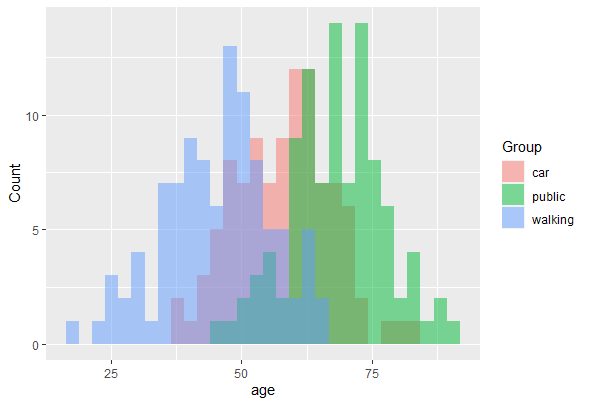
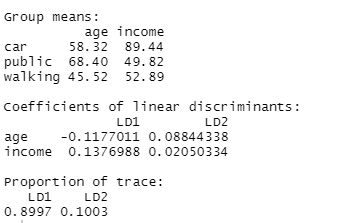
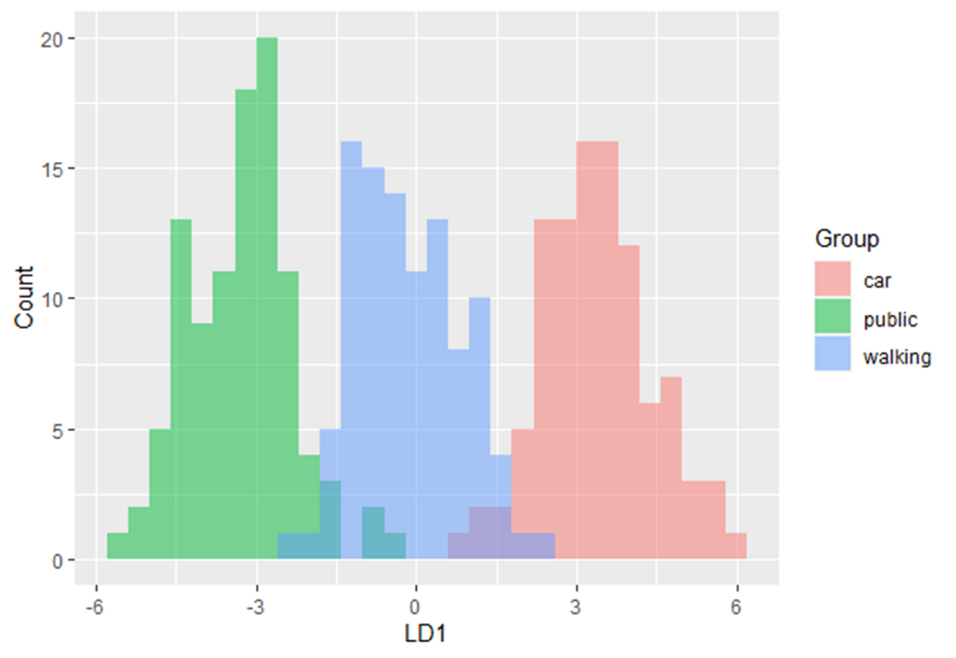
En este módulo de formación se te introducirá en el uso del Análisis Discriminante Lineal (LDA). LDA es un método para encontrar las combinaciones lineales de variables que mejor separan las observaciones en grupos o clases, y fue desarrollado originalmente por Fisher (1936).
Este método maximiza la relación entre la varianza entre clases y la varianza dentro de clase en cualquier conjunto de datos concreto. De este modo, se maximiza la variabilidad entre grupos, lo que se traduce en una separabilidad máxima.
El LDA puede utilizarse con fines puramente clasificatorios, pero también con objetivos predictivos.
Boedeker, P., & Kearns, N. T. (2019). Linear discriminant analysis for prediction of group membership: A user-friendly primer. Advances in Methods and Practices in Psychological Science, 2, 250-263.
Related training material






