DataScience Training
 Riprodurre l’audio
Riprodurre l’audio 










Keywords
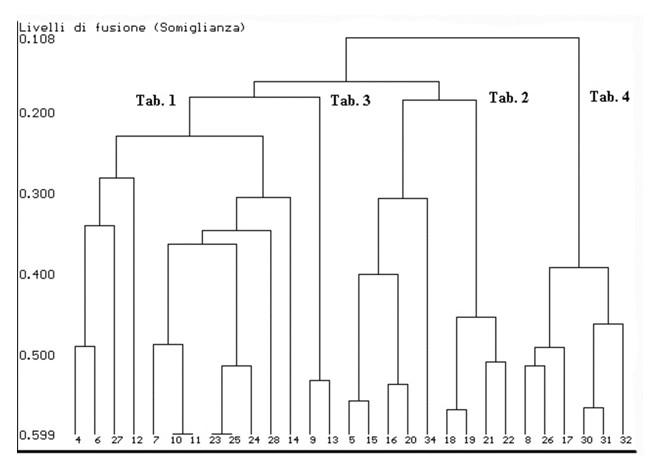
Unità statistiche, cluster, intra-cluster, inter-cluster, indice di dissimilarità, distanza di fusione, dendogramma.
Objectives/goals:Obiettivo di questo modulo è introdurre e spiegare la tecnica dell'Analisi in Cluster.
Alla fine di questo modulo sarai in grado di:
- Conoscere la logica dell’Analisi in Cluster
- Conoscere i requisiti
Condurre un analisi in cluster
In questo modulo formativo verrà presentata la tecnica di analisi multidimensionale denominata Analisi in Cluster, detta anche analisi automatica dei gruppi.
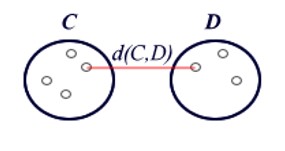
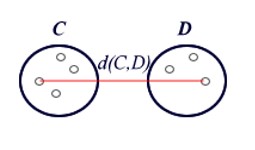
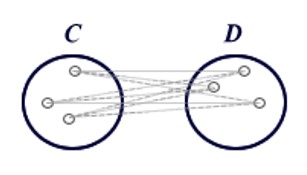
Le cluster analysis sono utilizzate per raggruppare unità statistiche che hanno caratteristiche in comune ed assegnarle a categorie non definite a priori. I gruppi che si formano devono essere il più possibili omogenei all’interno (intra-cluster) ed eterogenei all’esterno (inter-cluster).
L’applicazione di questo tipo di analisi è molteplice: informatica, medicina, biologia, marketing.
L’ultima parte del modulo sarà dedicata all’applicazione dell’analisi in cluster con il software R.
Related training material






