|
Text Mining
Einführung
Was ist Text-Mining? Click to read 
• Text-Mining ist ein Zusammenfluss von natürlicher Sprachverarbeitung (Natural Language Processing), Data Mining, maschinellem Lernen und Statistiken, die verwendet werden, um Wissen aus unstrukturierten Textdaten zu gewinnen.
• Generell lässt sich Text-Mining in zwei Arten einteilen
➢ Die Fragen der Nutzer:innen sind sehr klar und spezifisch, aber sie kennen die Antwort auf die Fragen nicht
➢ Die Nutzer:innen kennen nur das allgemeine Ziel, haben aber keine spezifischen und eindeutigen Fragen.
Text-Mining Herausforderungen Click to read
• Text in natürlicher Sprache ist unstrukturiert
• Die meisten Data-Mining Methoden verarbeiten strukturierte oder halbstrukturierte Daten => die Analyse und Modellierung von unstrukturiertem Text in natürlicher Sprache ist eine Herausforderung.
• Text-Data-Mining ist de facto eine integrierte Technologie der natürlichen Sprachverarbeitung (natural language processing bzw. NLP), der Musterklassifizierung und des maschinellen Lernens.
• Das theoretische System von NLP ist noch nicht vollständig etabliert.
• Die Hauptschwierigkeiten die beim Text-Mining eine Rolle spielen, ergeben sich durch:
➢ das Auftreten von Rauschen (noise) oder falsch formulierten Ausdrücken,
➢ Mehrdeutige Ausdrücke im Text,
➢ Schwierigkeiten beim Sammeln und Annotieren von Daten zur Förderung maschineller Lernmethoden,
➢ die Schwierigkeit, auszudrücken, was der Zweck und die Anforderungen von Text-Mining sind
Text-Mining Ablauf Click to read
•Text-Mining führt einige allgemeine Aufgaben aus, um Texte, Dokumente, Bücher und Kommentare effektiv zu minen:
Text-Mining Techniken
Übliche Text-Mining Techniken Click to read
Text-Mining ist ein Forschungsfeld, das mehrere Technologien und Techniken umfasst:
➢ Textklassifikationsmethoden unterteilen einen gegebenen Text in vordefinierte Texttypen.
➢ Text-Gruppierungs (Clustering) Techniken unterteilen einen gegebenen Text-Datensatz in verschiedenen Kategorien.
➢ Themenmodelle = statistische Modelle, die verwendet werden, um die Themen und Konzepte zu ermitteln, die hinter Wörtern im Text verborgen sind.
➢ Die Text-Stimmungsanalyse (Text Opinion Mining) deckt die subjektiven Informationen auf, die von einem:einer Autor:in eines Textes geäußert werden, d.h., die Sichtweise und Einstellung des:der Autor:in. Der Text wird basierend auf der im Text zum Ausdruck gebrachten Einstellungen oder Beurteilungen zu seiner positiven oder negativen Polarität klassifiziert.
➢ Die Themenerkennung bezieht sich auf die Ermittlung und Überprüfung von Textthemen (hochaktuelle Themen), die für die Analyse der öffentlichen Meinung, des Social Media Computing und der personalisierten Informationsdienste zuverlässig sind.
➢ Informationsextraktion bezieht sich auf die Extrahierung von Sachinformationen wie z.B. Entitäten, Entitätsattributen, Beziehungen zwischen Entitäten und Ereignissen aus unstrukturiertem und halbstrukturiertem Text in natürlicher Sprache, die sie in eine strukturierte Datenausgabe umwandeln.
➢ Die automatische Textzusammenfassung generiert automatisch Zusammenfassungen unter Verwendung natürlicher Sprachverarbeitungsmethoden.
Techniken zur Datenaufbereitung und -transformation Click to read
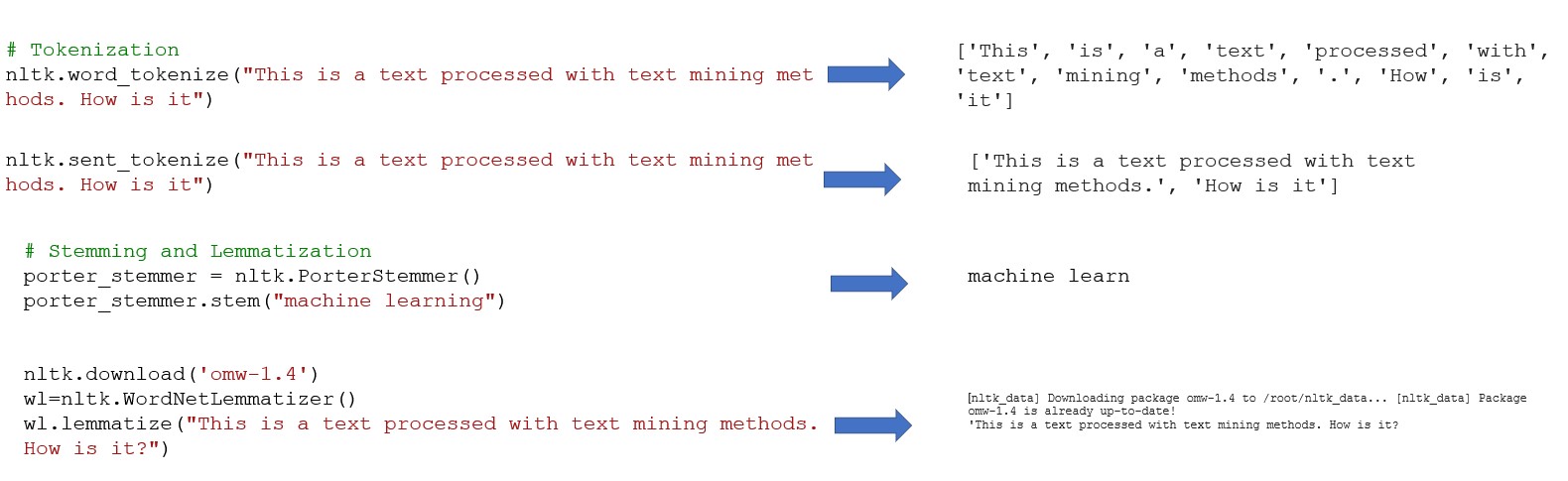
• Tokenisierung bezieht sich auf einen Prozess der Segmentierung eines gegebenen Textes in lexikalische Einheiten (isolierte Wörter)
• Entfernen von Stoppwörtern: Stoppwörter beziehen sich hauptsächlich auf funktionale Wörter, einschließlich Hilfswörter, Präpositionen, Konjunktionen, Modalwörter und andere häufig vorkommende Wörter.
• Wortformnormalisierung zur Verbesserung der Effizienz der Textverarbeitung. Normalisierung der Wortform umfasst zwei Grundkonzepte
➢ Lemmatization - die Wiederherstellung deformierter Wörter in ihre ursprüngliche Formen, um semantische Vollständigkeit zu gewährleisten
➢ Stemming - der Prozess des Entfernens von Affixen, um Wurzeln zu erhalten.
• Die Annotierung von Daten stellt eine wesentliche Phase des Überwachten Lernens (Supervised Learning) dar. Wenn der Umfang der annotierten Daten größer ist, ist die Qualität höher, und wenn die Abdeckung breiter ist, ist die Leistung des trainierten Modells besser.
Grundlagen der Textdarstellung (Text Representation) Click to read
Grundlagen der Textdarstellung (Text Representation)
• Das Vektorraummodell (Vector Space Model) ist die einfachste Methode der Textdarstellung
• Verwandte grundlegende Konzepte:
➢ Text ist eine Folge von Zeichen mit bestimmter Granularität, wie zum Beispiel Phrasen, Sätzen, Absätzen oder ganzen Dokumenten.
➢ Begriff ist die kleinste untrennbare Spracheinheit, die Zeichen, Wörter, Sätze usw. bezeichnen kann.
➢ Begriffsgewichtung ist die Gewichtung, die einem Begriff nach bestimmten Prinzipien zugewiesen wird und die Bedeutung und Relevanz dieses Begriffs im Text angibt.
• Das Vektorraummodell geht davon aus, dass ein Text die folgenden zwei Anforderungen erfüllt: (1) jeder Begriff ti ist einzigartig, (2) Begriffe haben keine Reihenfolge.
Text Representation
• Das Ziel von Deep Learning für die Textdarstellung (Text Representation) ist es, niedrigdimensionale, dichte Textvektoren mit unterschiedlicher Granularität durch maschinelles Lernen zu erlernen.
• Das Bag-of-Words-Modell ist die beliebteste Textdarstellungsmethode bei Text-Data-Mining-Aufgaben wie z.B. der Textklassifizierung und der Stimmungsanalyse.
• Das Ziel der Textdarstellung ist es, eine gute Darstellung zu konstruieren, die für bestimmte NLP-Aufgaben geeignet ist:
➢ Für die Stimmungsanalyse ist es notwendig mehr emotionale Attribute zu verkörpern.
➢ Für Aufgaben zur Themenerkennung und -verfolgung müssen mehr Ereignisbeschreibungsinformationen eingebettet werden.
Textklassifizierung Click to read
Textklassifizierung
• Bei der Textklassifizierung muss ein Dokument für Klassifikationsalgorithmen korrekt und effizient dargestellt (repräsentiert) werden.
• Die Wahl eines Textdarstellungsverfahrens hängt von der Wahl des Klassifikationsalgorithmus ab.
Grundlegende Algorithmen für maschinelles Lernen zur Textklassifizierung
• Algorithmen zur Textklassifizierung:
➢ Naive Bayes ist eine Sammlung von Klassifikatoren, die auf Basis der Prinzipien des Satzes von Bayes funktionieren. Naive Bayes modelliert die gemeinsame Verteilung p(x, y) der Beobachtung x und ihrer Klasse y.
➢ Maximum Entropy (ME) ordnet die gemeinsame Wahrscheinlichkeit von Beobachtungs- und Markierungspaaren (x, y) basierend auf einem log-linearen Modell zu:
|
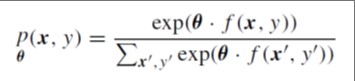
|
wobei: θ ein Gewichtungsvektor ist, f eine Funktion ist, die Paare (x, y) auf einem Merkmalsvektor mit binären Werten abbildet
|
➢ Support Vector Machines (SVM) ist ein baufsichtigender, abgrenzender Lernalgorithmus für die binäre Klassifikation.
➢ Ensemble-Methoden kombinieren mehrere Lernalgorithmen, um eine bessere Vorhersageleistung zu erzielen als jeder der base learning algorithms allein.
Einführung in Themenmodelle (Topic Models) Click to read
Einführung in Themenmodelle (Topic Models)
• Topic Models bieten eine Konzeptdarstellungsmethode, welche die hochdimensionalen dünn besetzten Vektoren im traditionellen Vektorraummodell in niedrigdimensionale dichte Vektoren umwandelt, die den Fluch der Dimensionalität (curse of dimensionality) abschwächen. Topic Models können Polysemie und Synonymie besser erfassen und implizite Themen (auch Konzepte genannt) in Texten gewinnen bzw. abbauen.
• Grundlegende Topic Models:
➢ Latent Semantic Analysis (LSA) repräsentiert einen Textabschnitt, gekennzeichnet durch eine Reihe von impliziten semantischen Konzepten im Gegensatz zu expliziten Begriffen im Vektorraummodell. LSA reduziert die Dimension der Textdarstellung, indem k latente Themen anstelle von m explizite Begriffe ausgewählt werden
Sie bildet die Grundlage für die Textdarstellung unter Verwendung der folgenden Zerlegungsmatrix
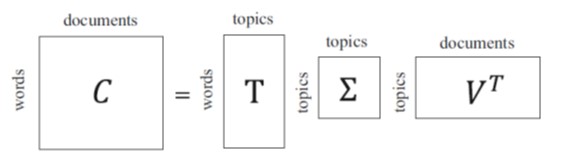
➢ Probabilistic Latent Semantic Analysis (PLSA) erweitert den Rahmen der LSA-Modell Algebra um jene der Wahrscheinlichkeit.
➢ Latent Dirichlet Allocation (LDA) führt eine Dirichlet-Verteilung in die dokumentbedingte Themenverteilung und die themenbedingte Begriffsverteilung ein.
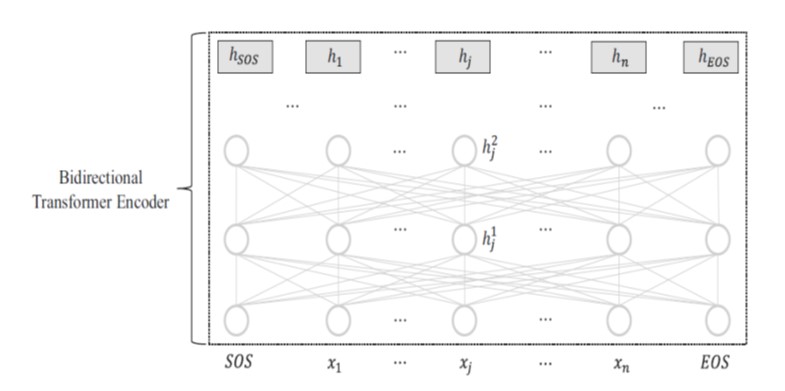
BERT: Bidirectional Encoder Representations from Transformer
•BERT ist ein Vortrainings- und Fine-Tunig-Modell, das den bidirektionalen Encoder von Transformer verwendet.
•Die Darstellung jedes Eingabetokens hj wird gelernt, indem sowohl der linke Kontext , x 1 , · · · , xj −1 als auch der rechte Kontext xj +1 , · · · , xn beachtet wird.
•Bidirektionale Kontexte sind entscheidend für Aufgaben wie das sequentielle Bezeichnen (labeling) und das Beantworten von Fragen.
•Kurzer Steckbrief zu BERT:
➢ BERT verwendet ein viel tieferes Modell als GPT, und der bidirektionale Encoder besteht aus bis zu 24 Schichten mit 340 Millionen Netzwerkparametern.
➢ BERT entwirft zwei nicht überwachte objektive Funktionen, einschließlich des maskierten Sprachmodells und der Vorhersage des nächsten Satzes.
➢ BERT ist auf noch größere Textdatensätze vortrainiert.
Stimmungsanalyse und Opinion Mining Click to read
• Zu den Hauptaufgaben der Stimmungsanalyse und des Opinion Mining gehören die Extrahierung, Klassifizierung und Inferenz von subjektiven Informationen in Texten (wie z.B. Gefühlen, Stimmungen, Meinungen, Einstellungen, Emotionen, Haltungen).
• Stimmungsanalysetechniken werden grundsätzlich in zwei Kategorien unterteilt:
➢ Regelbasierte Methoden: Stimmungsanalysen mit unterschiedlichen Textkörnungen basieren auf der Stimmungsorientierung von Wörtern, die von einem Stimmungslexikon bereitgestellt werden
➢ Auf maschinellem Lernen basierende Methoden konzentrieren sich auf effektives Feature-Engineering für Textdarstellung und maschinelles Lernen.
Fallstudie mit Python
Gängige Python-Bibliotheken für Text Mining Click to read
Gängige Python-Bibliotheken für Text Mining
➢ NLTK (Natural Language Toolkit) – enthält leistungsstarke Bibliotheken für die symbolische und statistische Verarbeitung natürlicher Sprache, die mit verschiedenen Maschinenlerntechniken arbeiten können.
➢ SpaCy - Open-Source-Bibliothek für NLP in Python, die entwickelt wurde, um Informationen zu extrahieren und die allgemeingültige natürliche Sprache zu verarbeiten.
➢ Die TextBlob-Bibliothek bietet eine einfache API für NLP-Aufgaben wie Wortart-Tagging, Extrahierung von Nominalphrasen, Stimmungsanalyse, Klassifizierung, Übersetzung und mehr.
➢ Stanford-NLP enthält Werkzeuge, die in einer Pipeline nützlich sind, um Zeichenfolgen mit Text in menschlicher Sprache in Listen mit Sätzen und Wörtern umzuwandeln. Weiter werden Grundformen dieser Wörter, ihre Wortarten und morphologischen Merkmale generiert und eine syntaktische Strukturabhängigkeitsanalyse erstellt, die entworfen wurde, um parallel in mehr als 70 Sprachen zu zu agieren.
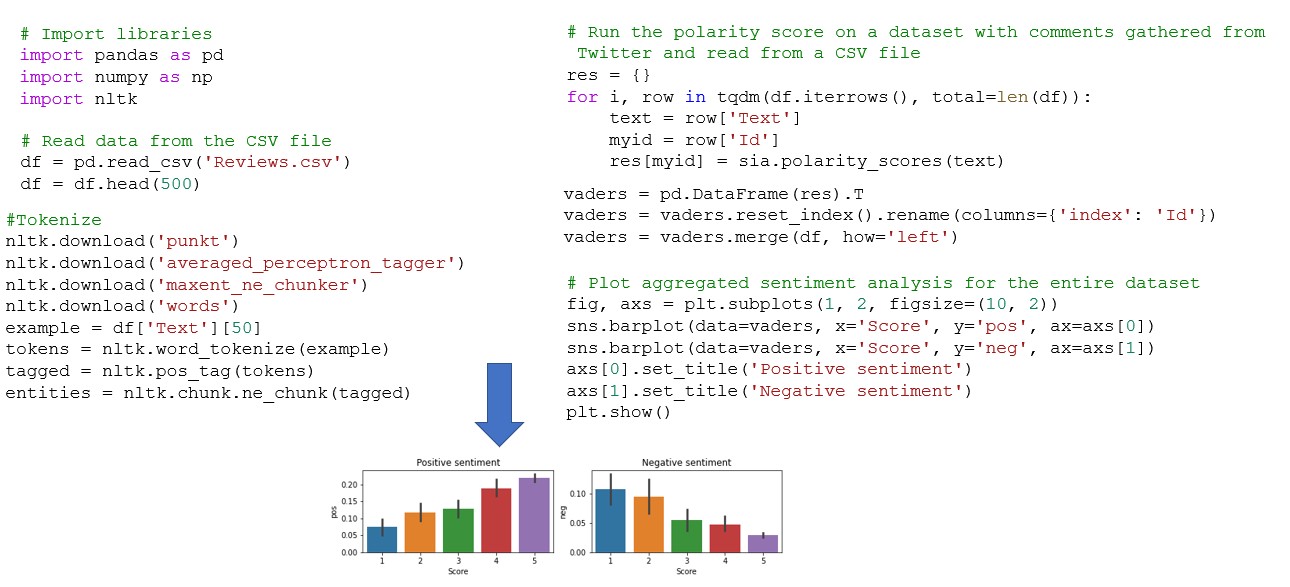
Verwendung von NTLK-Bibliotheken für Text Mining Click to read Stimmungsanalyse am Beispiel der Bag-of-Words- Methode und NLTK- Bibliothek Click to read Textklassifizierung mit Naive Bayes Click to read
Prognostiziere die Stimmung einer bestimmten Bewertung mithilfe eines maschinellen Lernmodells von Naive Bayes.

Zusammenfassung
Zusammenfassung Click to read |